To Understand Linear Algebra, let us make up a small day to day scenario.
Consider Surya goes to market every day and buys fruits. Surya went for past consecutive three days. Every day Surya bought apples, oranges and pineapples. Surya remembers the total cost that incurred but does not remembers what was the cost of 1 apple, 1 orange and 1 pineapple the seller sold.
Here are the 3 empirical outcomes, since it is consecutive three days, the fruits price might not have varied much, let us have it this way.
1. 3 apples, 2 oranges and 4 pineapple costed 270
2. 2 apples, 5 oranges and 3 pineapple costed 230
3. 6 apples, 3 oranges and 1 pineapple costed 250
and now Surya has to find out cost of 1 apple, 1 orange and 1 pineapple? That is when Surya try to solve these above equations.
we can form a equation as below.
[ 3, 3, 4, 580
2, 5, 3, 420
6, 3 1 , 200]
what we want is (below given is not exact figures or exact solution)
[1, 0, 0, 40 => implies 1 apple = 30 bugs
0,1, 0, 10 => implies 1 orange = 10 bugs
0, 0, 1, 25] => implies 1 pineapple = 40 bugs
So, you can see, What we always want is the diagonal matrix which is the solution to the given linear equations. Also see that what we mostly prefer is Identity Matrix. Reaching this diagonal matrix is not easily possible. so we go for first creating zeros in low triangular and then in the upper triangular. By scaling individual equations or by adding/subtracting 2 linear equations or by performing both.
These kind of calculation we must have performed in our schools as well, solving simultaneous linear equations.
apples, oranges and pineapples are dimensions, 3 dimension can be given with examples, consider 100s of dimensions what we will deal at work.
For 3 variables/dimensions, we definitely require 3 equations with all three variables involved in forming equation.
For n variables/dimensions, we definitely require n equations with all three variables involved in forming equation. Unless there are equations which involves less than n variables.
Can the diagonal element be zero?
For a matrix to be upper triangular or lower triangular matrix, zero in the diagonal does not matter, but for matrix to have a solution there should not be any zero in the diagonal. Zero in the diagonal means, Determinant of the matrix is zero. Zero in the diagonal means matrix inverse cannot be found since it is equal to adjunct of matrix divided by determinant.
What are Determinant and Adjacent?
Our objective is to convert a given system of linear equation into matrix and then into an Identity matrix to get the solution. How will we do this?
If we restate the same. we want all elements to be zero except for diagonal.
Consider this, does the below statement make a difference?
3 apples, 2 oranges and 4 pineapple cost 270
2 oranges, 4 pineapple and 3 apples cost 270
As for the particular equation is concerned they are the same, the order of counting cost does not matter to find the total cost.
When we have system of equations, We have to shift the entire column, not just, the one element in the column. Because we want to compare apples to apples and do some manipulations like addition, subtraction.
Can I switch 2 equations? Will moving an equation above & below make any difference?
Does the order of days when Surya went to market matters? No. Hence order of equation also does not matters.
So, we are given with these 2 freedom of movements/rearranging the matrix.
1. equation switch
2. dimension switch
I have just given row & column switch/interchange a different meaningful names.
The above 2 freedom of movement did not do anything to the matrix, even to the numbers in the matrix. It just shuffles.
Consider this, will doubling the fruit count, double the total? Yes.
[3 apples, 2 oranges and 4 pineapple costed 270] then [6 apples, 4 oranges and 8 pineapples must be costing 540].
We have just multiplied the equation with 2, it could be any number other than 2. While doing so we see that we do not Touch the Other equations.
we can add and subtract two equations, given that we do the operation on co-efficient of same dimension and the operation is also done on corresponding cost.
There are 2 freedom of manipulations of equations
1. Addition/Subtraction between 2 equation.
2. Multiplication/Division of an equation by constant factor.
Can't we make a Commodity Exchange? Replace Apple with equivalent costing Oranges?
We can do it, but we have to do it simultaneously in all equations, not in only one equation as we really do not know the cost of each yet,. While doing so we see that we do not Touch the Total Cost.
we can add and subtract two commodities/dimension as well, given that we do the operation on co-efficient of different dimension.
There are 2 freedom of manipulations of dimensions
1. Addition/Subtraction between 2 commodities/dimension.
2. Multiplication/Division of commodities/dimension by constant factor.
The 6 freedom of moves that we could make on the game. They are the rules of game - THE MATRIX.
Can we treat the Total Cost also as a dimension/commodity? By that we question whether switch them and manipulate them along with other dimension/commodity allowed?
No, We should not, it is not a commodity or dimension. It is just a constant and not a variable co-efficient.
Now we know moves of each pieces on a Chess Board, sorry MATRIX ;) we should now form a Strategy.
Our goal is to reach Identity Matrix, we can have sub goals.
Either to attain LOWER triangular matrix first and the attain Identity Matrix or attain UPPER triangular matrix and the attain Identity Matrix. So Triangular Matrices are our Sub goals.
Sometimes, we attain only sub goal and the take the solution without attaining Identity Matrix via Substitution method.
There are few Strategies that have some special names,
1. Gauss Elimination Method & Substitution
Attain first UPPER TRIANGULAR Matrix via freedom of movement and manipulations especially Row reduction. By now you could have got the cost of at least one commodity or dimension value. substitute them on other equations to get the cost of other commodities or dimension values.
What is Row reduction? - A reduction operation is an operation which reduces a number down to zero. If the reduction is done row wise, in this cases with manipulation between 2 equations. It is called row reduction.
If the reduction is done with columns/commodities/dimension it is called as column reduction.
2. Gauss Jordan Method
Attain first UPPER TRIANGULAR Matrix by row reduction and then attain Identity matrix with column reduction.
All these Operations if we code in a program looks to be cost intensive, what if we want the solution straight forward?
That is when we require determinants and adjuncts or cofactors
Determinants takes its root from DETERMINE.
Adjunct means a thing that is added or joined to something larger or more important. (small matrix of big matrix)
What determines the cost of Apples?
The cost of Oranges and Pineapples determines the cost of Apples as the total cost is a CONSTANT value.
In Matrix, for each element in each equation has determinants they are called as MINORS.
We do mining in these area to calculate adjunct and determinant and then to calculate A-1 (A inverse) for square matrix only. All we need is Identity A-1.A (A inverse matrix multiplied by A) is Identity I.
3x+2y=17
2x+3y=18
[3 2 17
2 3 18]
Determinant = 3x3 -2x2 = 5
Minor Matrix [3 -2
-2 3]
Adjunct or transpose of Minor Matrix = [3 -2
-2 3]
A-1 = ( adjunct / det of matrix) = [ 3/5 -2/5
-2/5 3/5]
A-1 B = [ 3/5 -2/5 [ 17
-2/5 3/5] 18]
= [3
4]
x =3, y =4
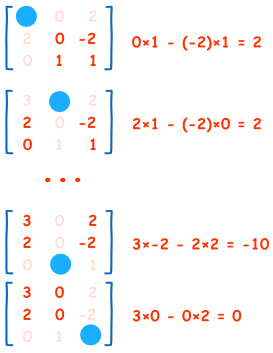
and get MATRIX of Minors.

These minors affect the actual via Co-factors.


By Transposing the Matrix of Co-factors we get Adjunct
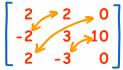
Cramer Rule goes one step further gives the solution directly with Determinants only


I felt little happy as Determinants alone is sufficient to get the solution, but it is not the case practically it seems.
Though Cramer's rule is important theoretically, it has little practical value for large matrices, since the computation of large determinants is somewhat cumbersome. (Indeed, large determinants are most easily computed using row reduction.) Further, Cramer's rule has very poor numerical properties, making it unsuitable for solving even small systems reliably, unless the operations are performed in rational arithmetic with unbounded precision.
References: