Why you should read this blog? What will be your takeaway?
1. Better Understanding of "Data Mining"
2. Picture data mining perfectly among the misty jargon
3. Helps to understand a student's journey.
It was my first Data Mining class of M.Tech in Data science. I was not completely focused during the class hour as the class lecture bewildered me to think What is Data Mining?
Is the word "Mining" in "Data Mining" Misleading?
I started looking for the difference between data science and data mining. My Initial though was that "Data Mining" is nothing but data collection. I thought so because, when i went through "Statistical Mathematics", the collection and cleaning of data for performing some analysis itself was huge task. Consider the age where there was no social media and no internet. Statistics had its birth out of mathematics especially probability theory. Census was very much important for proper governance during that era and people have to visit each household, each and every village and cities to collect data. Consider every revolution any country had seen. At all these revolution huge of amount of data was required and people did collect from every required corner of the globe to bring in revolutions. So was my assumption that "Data Mining" is collection of data.

| Black Revolution | Related with Petroleum Production |
| Blue Revolution | Related with Fish Production |
| Brown Revolution | Related with Leather, Cocoa |
| Golden Fibre Revolution | Related with Jute Production |
| Golden Revolution | Related with Overall Horticulture, Honey, Fruit Production |
| Green Revolution | Related with Agriculture Production |
| Grey Revolution | Related with Fertilizers |
| Pink Revolution | Related with Onions, Prawn |
| Red Revolution | Related with Meat, Tomato Production |
| Evergreen Revolution | Intended for overall agriculture production growth |
| Round Revolution | Related with Potato Production |
| Silver Fibre Revolution | Related with Cotton Production |
| Silver Revolution | Related with Egg Production |
| White Revolution | Related with Dairy, Milk Production |
| Yellow Revolution | Related with Oil Seed Production |
| Round Revolution | Related with Potato |
Hopes turned despair and I was confused
More through the lecture my hopes were turning into disparity as the lecture took a direction different from "Data Collection". The course of the lecture was not anywhere near how to collect data, where to find for sources. How to select the sources. I started reading about the difference between Data Mining and Data Science. Instead of clearing my doubts, it catalyzed my already burning confusion.
Here is the site, I checked out .
I came across other names of "Data mining"
1. Data Archaeology
2. Data Discovery
3. Information Harvesting
4. Knowledge Extraction
Got confused and started thinking more in terms of Archaeology. Selecting site for digging after a long and thorough analysis of histories (like keeladi site excavation), theories and speculating few finding based on other findings in hand. Looks I am right, data mining seems to be data collection, but collection of data from rare sites and collection of Golden Nuggets among the debris.
With the term Data Discovery, I can say, Discovery of natural phenomenon have never been straight forward, 99.999999%, human just stumbled upon them. While "Need is mother of all Inventions", discovery unlike it has a bizzare path. Discovery has everything to do with Nature. One has to look into to Nature to discover as one is just finding what is there all the time, while invention is just a process of putting things together as per the need. Only once in a while someone discovers something meaningful in the era in which he discovers.
While thinking about Information harvesting, when did we sow the seeds to grow data to harvest?. Yes, we do sow the seeds via all our OLTP systems. Consider every form we fill to give our personal details or fill some events as part of job or fill workflow input data to generate events. Forms are our fields, input data are our seeds. Data grows in velocity, variety and volume to produce Information and we harvest Information.
While thinking about Knowledge Extraction, Knowledge is nothing but Connecting dots of Information.



None of the other names of "Data Mining" brought clarity. Data Mining, Data Archaeology and Data Discovery point a direction towards searching dirty data pile, while Knowledge discovery and Information Harvesting point out the act of extracting the Golden Nuggets.
Classify the data to get information, connect information to get knowledge. Exercising the knowledge at the required situation or context in a globally acceptable way is wisdom. Wisdom creates an impact. All is well. Yet what is data Mining?

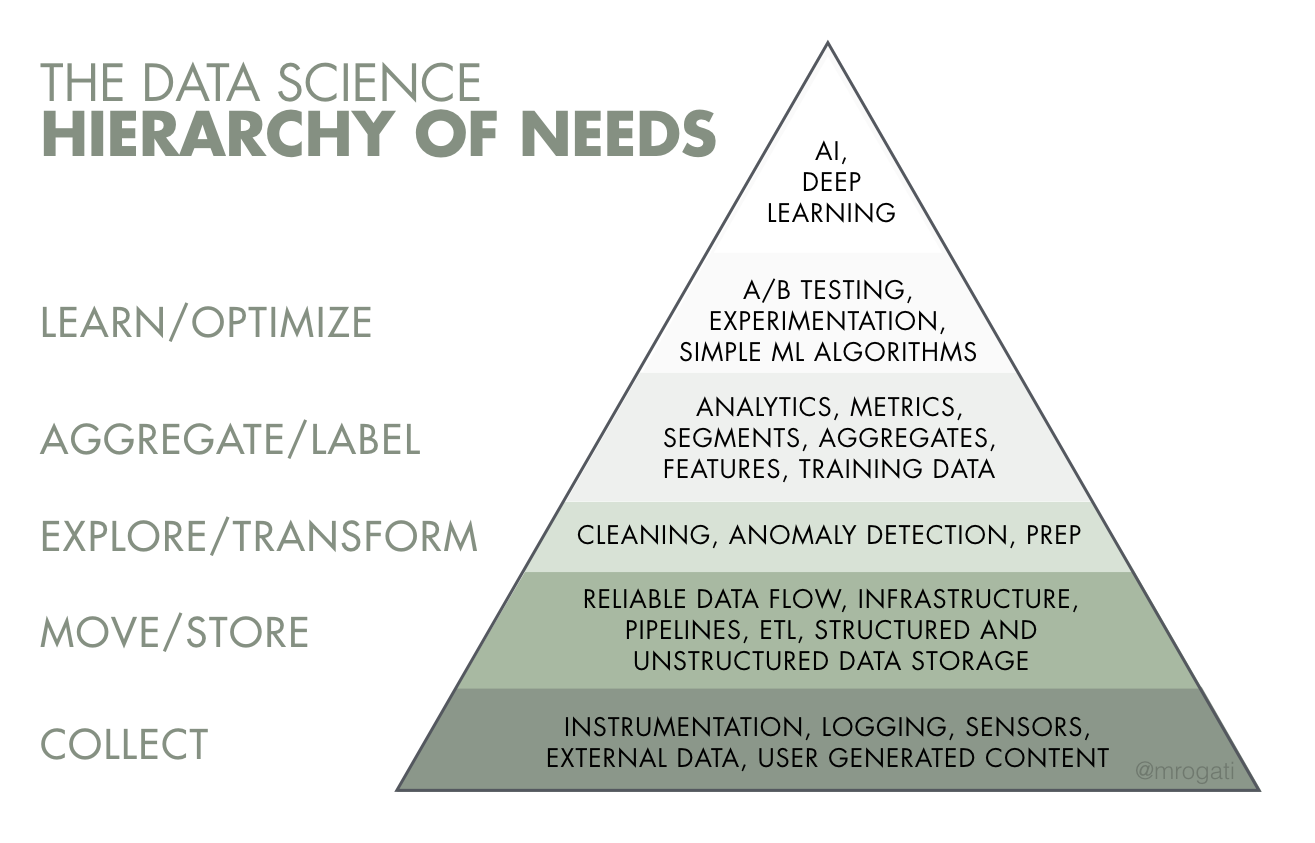
 Better Picture of the "Extraction of Golden Nuggets" Appeared
Better Picture of the "Extraction of Golden Nuggets" Appeared
Given the confusion, i started searching for images and more clarification linking data science and data mining.



With the above images, I hit the jackpot. Everything fell into the singularity. With data science we seem to analyze the past to predict the future by penetrating the data via analysis, then analytics - automating analysis a bit with logic(completely analytical math), then with data mining - proactively making sense with heuristics with causation and correlation of different dimensional data.
The above stated comparison seems sufficient. I think we should never compare the data mining & tasks (mostly i see classification, regression etc.,) with storage systems like data lakes and data warehouses, techniques & tools like statistics methods or BI tools or Machine learning and Roles like Data Engineer, Data Scientists, Data Analyst, despite they are required while performing Data mining. Confusing roles, storage, technique and methods seems to be the cause of ill. At least I was receiving some information so and so during the lecture with my antenna.
Given the relief I shared one more link which I read to differentiate "Data lakes" and "Data Warehouses" with my class students -
here it is.
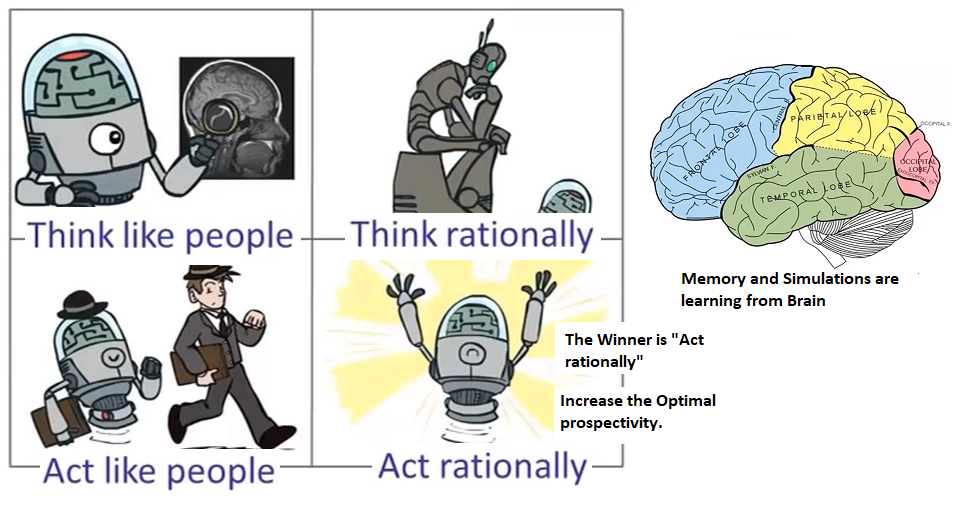
To conclude, Data Mining is a Technique, focused on Business Process to extract Patterns of Information with the purpose of finding trends previously not found. In order to perform data mining, one has to have the understanding of data whereabouts in order to navigate across and its statistical understanding to conduct Mining operation. It is a part of Data Science to conduct Data Mining on Structured data while dealing with both structured and unstructured data. AI is part of Data Mining. There are 4 perspectives for AI. Only one winner which is what is required for Data science and the Winner is "AI which acts rationally and achieves result in optimal expense of resources (time & memory) while applying heuristics over data mine field. Machine learning and deep learning or anyway a part of AI and so they become part of Data Mining.

P.S - The lecture also expounded some business areas where data mining is applied but i was not able to appreciate them without proper understanding or definition of the term "Data Mining" itself. Hope I missed it or lecture never had it.