My journey with Special Matrices started with Transpose Operation, you can read about it in this post as you could find few interesting ones already over there.
There are so many number of special matrices(named matrices), but we shall see few of them.
In the previous blog, we saw that Unitary MatrixU has property U∗U = U∗U =I. I being Identity.
In the previous blog, we saw that Orthogonal Matrix has property ATA = AAT = I, I being Identity.
I found that few matrices are named as Normal Matrices. When A*A = AA* but need not be equal to I (identity matrix). Among complex matrices, all Unitary, Hermitian, and skew-Hermitian matrices are normal. Likewise, among real matrices, all orthogonal (ATA = AAT = I), symmetric (ATA = AAT), and skew-symmetric (ATA = AAT) matrices are normal. However, it is not the case that all normal matrices are either unitary or (skew-)Hermitian.
I found Symplectic matrixinteresting as i found it to be related to Transpose and Skew-Symmetric Matrix. It is a Dual Combo.
Symplectic matrix is a 2n × 2nmatrixMwith real entries that satisfies the condition
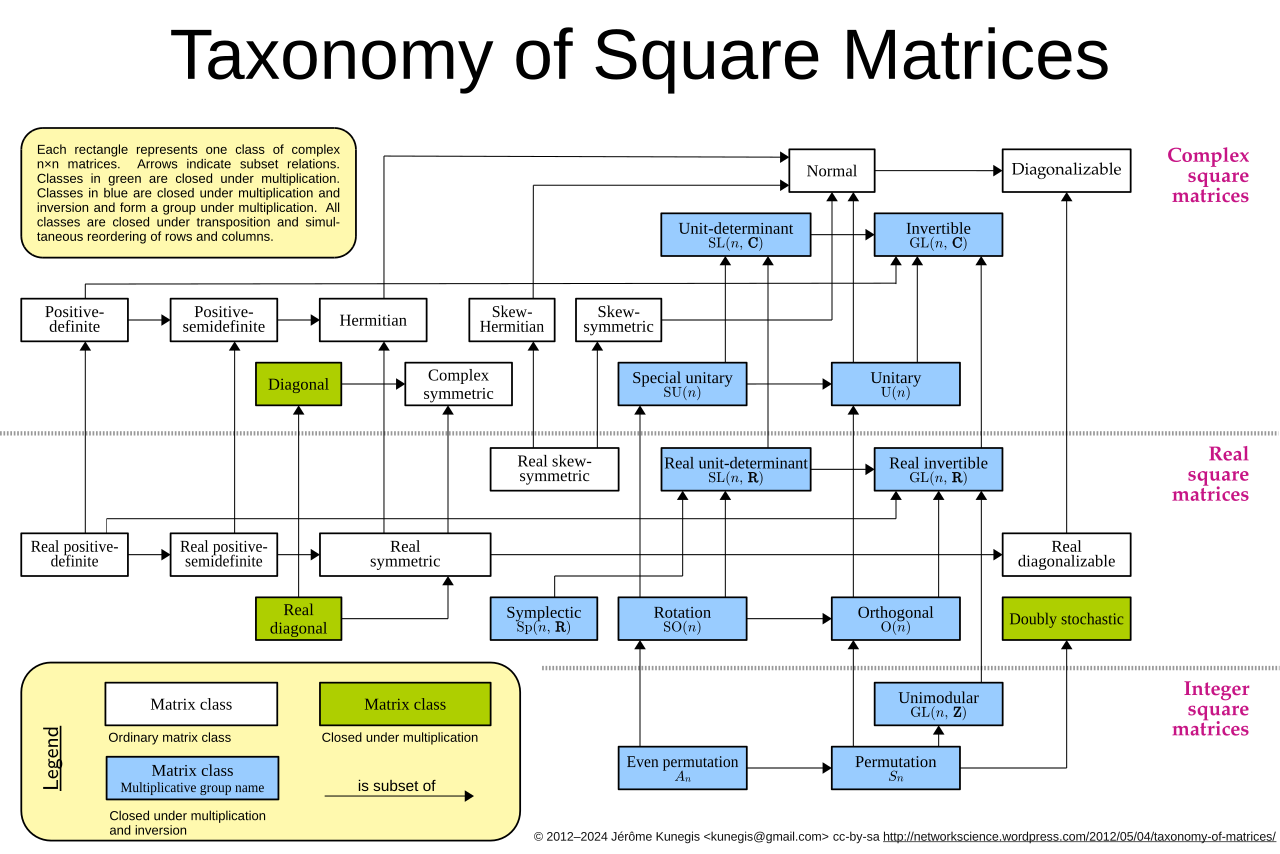
The below picture from wikipaedia, provides few named matrices and their relations. The wikipaedia page provides almost all present named matrices despite no relationship been identified. I have not gone through other interesting ones, may be they are for another blog.
Transpose it very simple operation to change rows into columns and columns into rows. I had never given any importance to this operation until i found the relationship between Transpose Operation with Special Matrices. For Example we prefer Transpose of Matrix A over Inverse of Matrix A when we find the matrix is Orthogonal.
Orthogonal Matrix is a special matrix, I thought it is the only case. The real surprise came in, when dealing with Real Skew Symmetric Matrix.
In this blog I like to capture the properties of Transpose Operation of Matrix and the relation of Transpose operation with Special Matrices.
Properties of Transpose Operation:
Let us see the properties
1. Inverse of Transpose: Transpose of Transpose
2. Transpose with Additivity
3. Transpose with Mulitiplicativity
4. Transpose with Scalar Multiplication
5. Transpose with Determinant
6. Share Same Eigen Values & Polynomial:
AT and A share same eigen values as they polynomial representation is same.
We have seen 10 properties of Transpose Operation. Now let us see What it has to do with Special Matrices. We shall start with simple special to very special and we shall see what special property arises with it.
This is a combination of both Skewed Matix and Hermitian.
If A is Unitary Matrix, We call a matrix U unitary if U−1 = U∗ or U∗U = UU∗ = I. Here * denotes conjugate transpose.
For a unitary matrix U, determinant of U is 1. Hence it is called Unitary Matrix.
In the above cases we can see how various complex operation can be replaced with Transpose Operation, It is very interesting to know the application of Transpose :)
You can also read more about Special Matrices my other post.
Orange is an wonderful training tool for new learning who are trying work with data mining. I was fortunate enough to go through the tutorial videos. I found the following things interesting in ORANGE.
1. Lot of interesting data sets available to learn.
2. Lot of Video Tutorial to start with 2 step workflow and gradually to move to specialization.
3. Few Example templates can be created in one click available for starters.
4. Data visualization like scatter plots, Hierarchical dendron diagram, linear regression charts, k-means clustering charts are possible.
5. It also does split the data into training, cross validation and test and does train models on various models like linear regression, classification and clustering models.
6. Interactive Selection: Selection of few data on chart pipelines the data into the next workflow component like "data table" or "scatter plot", which is some interactive UI, I did not expect.
7. Interactive K-means along with position of centroid was also possible.
8. Measures: From accuracy, confidence, Interstates measures, confusion matrix. Tools like euclidean distance, jaccard distance, almost all of them were available.
9. Addons: Education, Text, Image and geospace add on and lot more domain specific measures are also available.
10. It is easy to do PCA in a flick.
11. Paining Data: It is such a wonder feature, we can paint the spread of data just like a kid would paint on any painting tool
12. It seems to have been built on top of R, but it also provides packages to work with python.
The tool made me to realize that many measure are just drag and drop away and we can draw workflows and pipelines in a flick, but it is important to understand domain & measures and work on variety of datasets.
அறிவுடையோர் எதிர்காலத்தில் நிகழப்போவதை முன்னே எண்ணி அறியவல்லார், அறிவில்லாதவர் அதனை அறிய முடியாதவர்.
அஞ்சுவ தஞ்சாமை பேதைமை அஞ்சுவது
அஞ்சல் அறிவார் தொழில்.
அஞ்சத்தக்கதைக் கண்டு அஞ்சாதிருப்பது அறியாமையாகும், அஞ்சத் தக்கதைக் கண்டு அஞ்சுவதே அறிவுடையவரின் தொழிலாகும்.
எதிரதாக் காக்கும் அறிவினார்க் கில்லை
அதிர வருவதோர் நோய்.
வரப்போவதை முன்னே அறிந்து காத்துக் கொள்ளவல்ல அறிவுடையவர்க்கு, அவர் நடுங்கும் படியாக வரக்கூடிய துன்பம் ஒன்றும் இல்லை.
அறிவுடையார் எல்லா முடையார் அறிவிலார்
என்னுடைய ரேனும் இலர்.
அறிவுடையவர் (வேறொன்றும் இல்லாதிருப்பினும்) எல்லாம் உடையவரே ஆவர், அறிவில்லாதவர் வேறு என்ன உடையவராக இருப்பினும் ஒன்றும் இல்லாதவரே ஆவர்.
I don't like to Quote IQ, EQ, CQ, AQ and SQ, in general we can state them as, inter and intra personal skils. The above thirukkural states on how to employ "Arivu". The term "Arivu" is connotative to inter and intra personal skills and all the Qs together. It neither denotes intellect or intelligence, it denotes the wisdom.
It is stated that the person having such wisdom do know what is going to come and can handle it accordingly and they have all what they needed to handle various situations and they ensure any harmful situation don't occur by desiring neither to be sad nor to be happy but by remaining empty with whole heart to accept the entire world. They talk clearly and listen to people with much care and attention, they walk the way of the world and act according to the situation. They ensure that their act align with good deeds. Their openness and acceptance itself is providing enough security as they don't believe & act for individual security but for everyone's security.
Reference provided with gratitude for the below asset holders:
Above rule looks normal. Theorem 6, 7 and 8 are extra ordinary. They deal with exponential and logarithms properties.
At least 7 is understandable, based on exponent rule, we can remove coefficient x. Theorem 6 and 8 both deals with exponential, one on normal n another on log n. what do they mean?
Examples of the application of the above theorems.
Two function are comparable in Linear scales but once the rate of growth becomes exponential then it becomes difficult to compare them.
Logarithms provides a scale to understand algorithm for vert fast changing functions by comparing 1, 10, 100, 1000 range jumps on iteration.
Apart from log base 10, which is commonly used, we also use log base e, ln or natural logarithm. where e = (1+1/n)^n as n reaches infinity. Natural logarithms occurs in many natural events.
Richter scale to measure earth quake is logarithmic.
Please compare the functions and their growth rates. Here log n grows very slowly. It is an mirror image of Exponential, which grows damn faster.
Here are some rules of Logs
Here are some application of rules of logs.
More rules and special names of rules
The products becomes sums, divisions becomes subtraction, exponential becomes multiplication. Apart from these complex operations turning into simple operations. I find even in exponential function, we have same rules.
I find the following log function rules interesting.
1. a ^ logb = b^ log a => an Exchange rule.
2. log a (base b) = log a base c / log b base c => base change rule
3. Logarithm does not work in -ve & - infinity numbers. They stop at 1. Log(1) =0. Log of infinity is infinity.
Tip: Take log of two or more function whenever you find it difficult to compare especially when you have exponential functions. Apply logarithmic rules to simplify comparison.
1/log(x), when we take log becomes log(1) - log(log(x)).
when comparing log with 2 different bases. The log function whose base is larger is the one which has got folded a lot, hence it is smaller than the log function which has a smaller base.
I read in my school days that there is no side effects performing swimming and yoga when compared to other forms of exercises. It is just that belief, that pushed me to kick start with swimming and yoga. The word Yoga means to become one with the universe, it does not denote a form of exercise. I have been doing lot of yogic postures in my school days, to keep my body damn flexible and to compete with others. But the time is ripe for realizing the real form of yoga in term of meditation.
How did meditation changed me?
I have been doing meditation for around few months continuously, every morning and i did swimming for about a month and had stopped it due to Corona Outbreak. Doing both seems to have made my body and mind flexible.
I have lost weight of around 12 kilograms. Since I started doing meditation & swimming, I had been continuously loosing 3 kilogram per week and it got reduced from 75 and stabilized at 62 kilogram.
I changed my eating habits. I brought this change as eating and breathing are essential activities which we do regularly to keep life intact with body and I also find all the other activities subsidiary compared to them. I was conveyed that they are having a profound impact on the mind while I took 2 full day meditation program to kick start meditation. Now I realize how profound is the impact of food and breathing on the mind.
I stopped taking dinner at night, to avoid ulcer kind of problems I took milk and dates in limited quantity. Stopped taking tea and snacks at office. I tried them one by one, I did not even had any hope or I did not even gave any thought of my will power during this period, I just gave a try. I stopped my dinner with out a substitute. But for dropping tea/coffee and snack I did created a substitute, I took lot of water when I felt less energy, tea/coffee time was a strict "no" most of the time unless my energy dropped to make me feel very weak. I took tea/coffee and food at night occasionally, to keep my energy up. But it is still surprising how I was able to keep my energy up to such an extent that today, I am free of coffee/tea, snacks and heavy dinner.
I started to chew my food to such an extent that my salivary glands could digest most of carbohydrates in my mouth itself, so it leaves the stomach to digest protein and intestine to digest fat and lipids. This activity I started along with other trails that I had been performing while investigating the impact of food intake on body and mind. I reviewed human body structure and organization of nervous system, blood circulation system, lymphatic system and recollected the functioning of both endocrine and exocrine glands. It left me with a thought that our body is a huge and complex support system of life, it has various organizations, each organization has various communities and communities are formed by specialized cells to form body parts from skin to heart to brain, you name it. When we eat food each and every cell to cell organelles based on the gravity of attraction or repulsion (i.e., a very mild attractive and repulsive force) performs some move to make each organization to act in a certain way and these activities are happening in a rhythmic way through out the day based on the needs of each organelles in cells and the balance & imbalance they make with rest of the system. People have named this almost cyclic behavior happening everyday as "Circadian" rhythm. In India, we have terms such as Dinacharia and Ritucharia, here charia means path or following footsteps, dina stands for day, ritu stands for season. They represent the acts that we should do on daily basis and as per seasons. The acts seems to have been described based on the profound knowledge of the body as huge and complex support system and the cycle it goes through daily and seasonal. Changing a habit with these cycle is very difficult, apart from these we have external factors which demands us to remain in harmony with external world. I am happy that I could change it.
I wanted chew food thoroughly. To avoid junks food and to avoid pungent, very spicy, tangy or hot taste, I avoided taking outside foods. I also avoided onion and garlic as they make me difficult to keep the food little long in mouth to chew. Our tongue has become a lier over many years. The excitement signal the tongue sends to brain and the neurotic signals that it sends especially to salivary glands has kind of skewed. It takes some time for the salivary glands to secrete enough to digest the food, it takes a lot of chewing and ensuring we don't swallow the moment we intake food in our mouth.
Needless to say, my awareness of the body did increase with meditation. To support all the change and cause that was said so far, meditation played a major role, without which nothing could have been achieved.
What do i do in the name of meditation?
Meditation takes place for every living being, it happens to person who know nothing about the word "meditation". It is a shutdown and restart switch for entire body. Beware we should not shutdown our complex and humongous system if that is not our intended goal but meditation could do that. It can also put the system in to paused state for many days, months and years. In India, we call this shutdown state as jeevasamadhi, paused state as samadi, the act of touching samadi and coming back as performing meditation. Meditation is a thought, study and thorough reflecting of profound nature inside us and outside us.
There are various form of meditation, a book named appropriately as Vigyan Bhairava Tantra to manifest spiritual energy documents 112 meditation techniques, most of them are very simple, even a child could perform, for example gazing at light for long time is a kind of meditation. Meditating only with mind for me had been unattainable. To perform dynamic mediation, by letting mind to freely think and letting body free for several hours also has been unattainable. I see, that great saints never bothered about what technique they are following. Following a technique itself is wrong, as the technique may or may not work, to put us in balance with rest of our surroundings & events. But I found a mixed of physical activity and mental activity to calm down in my surrounding environment has helped a bit to perform balancing and also helped me to calm down.
With few physical yogic postures I am able to activate all 7 Chakras or the 7 largest synapses of nervous system that flows through spinal cord, right from perineum up until the brain. Physical acts can be done despite we have any state of mind that make it fool proof in not making mistake when we try to settle down each organs, cells and organelles. Each chakra activation ensures, that it takes care or activates/deactivates organs to gets enough oxygen from our lungs and prepares them for the next chakra activation or in general for next level. It shutdown down the system level after level and lets me to touch the epitome of silence and sometime with a blessed feeling.
For certain, when i woke up from my bed, I usually felt little tired. After performing meditation session I felt i had gained enough energy for the day. Nowadays, when i wake up from bed despite being tired, I feel happy because of the fact that a single mediation session could put me back on track for the rest of the day.
Mediation session does comes with a cost but it is like paying already borrowed loan, the cost will slowly diminish over a period of time. Initially, it takes hours without any outcomes or energy, until we get accustomed to it.
Here are my few tips,
1. Our thoughts are always wandering and judgmental. Observe what thought do come why we do them the way we judge them and re-frame what the thoughts.
2. Do not suppress thoughts. Sometimes it takes several minutes to realize that we are thinking in certain unwanted direction and we are not taking control of our thoughts. Let it fly during meditation session, observe them if few thoughts are taking several hours and mental energy, see what physical or mental act you could perform to settle your mind.
3. Observe, you being control of your thought, and you not being in control of your thoughts. The ups and downs are the way of life.
4. Focus thought on some object which you can describe and think for several hours. Observe the object vanishing from your thought and helping you to pause your entire system for sometime.
Witnessing and Observing is the key. One can repeat "Witness" as any kind of mantra. It creates a detachment. It is difficult to perfect our body, and to keep it in balance with the events around us. It is a moving target. It is easy to figure out what imperfection to address when we witness. Mind listens to body first than your rational brain. Witness it. It is very difficult to remain rational than irrational. Common sense is not common. Accepting "Common sense is not common" gives a different perspective. The way we see our life changes. It opens our heart. It expands our heart to make rooms for everyone, everything.
Documenting my today learning from BITS WILP webinar on MFDS.
Construct a linear transformation T : V --> W, where V and W are vector spaces over F such that the dimension of the kernel space of T is 666. Is such a transformation unique? Give reasons for your answer. if we have to divide the problem, we can do as following,
1. What do we mean by Unique Transformation.
2. What is kernel Space?
3. Does T : V --> W, where V and W are vectorspaces over F has any special meaning with F (i.e field)
4.What is the significance of Dimension of kernel space of T being 666
we will not be able to address the above question without knowing vector space and linear independence and linear transformation
What is a Field, Vector space and Subspace? * identity, - > * closure, -> * associative, -> * inverse -> Group -> (+,x) commutative -> Field -> (*,x) commutative -> Abelian Group.
* denotes any operation like + and x.
In vector space we have vectors (value + direction) defined with two operations vector addition and scalar multiplication. And it is a field as it obeys above said axioms.
A vector subspace is a non empty subset of vector space and it is a field with two operations vector addition and scalar multiplication. What is linear independence?
if linear combination of these vectors with coefficients zero results in zero and there is no other coefficient that make it zero then it is called Linearly Independent otherwise it is called linearly dependent. if coefficient are non zero but the combination results in zero, it has one or more solution other than trivial solution.
c1a(1) + c2 a(2) + … + cma(m) = 0
If at least one of the vectors as a linear combination of the other vectors, then the vectors are called Linearly Dependent.
The rank of a matrix A is the maximum number of linearly independent row vectors of A.
The max of linearly independent vectors which can be put in combination in V is Dimension of V and the such set of vectors is called the basis.
Anything lesser than max no. of linearly independent vectors can span a small subset of vectors in space, this no. of subset vectors spanned by the linearly independent vectors is span.
span = dimension, when subset of vector space forming linear independent vector & basis.
Standard basis are mostly the axis of Co-ordinate system like R^1, R^2, R^3 or 1D, 2D, 3D. Apart from that we have vector space of polynomial P1, P2, P3 or linear, quadratic, cubic and vector space of matrices M12, M13, M21, M22, M23, M31, M2. We can also extend the like upto R^n and P^n.
subspace of R^3 is R^2 and R^1 (a reduction in dimension is observed)
It is always good to check for the axioms getting satisfied or not before declaring a space as vector space.
Linear Transformation
Now we know what is vector space and linear independence. only after knowing it we could increase momentum and jump to understand Linear Transformation.
A Transformation is a function mapping domain to co-domain. Here a domain space is a Vector Space, it has a set of vectors, and co-domain space is also a Vector space, it has a set of vectors.
T: V -> U
A Transformation is linear only if it satisfies,
T(U+V) = T(U) + T(V)
T(kV) = kT(V)
Remember the MatrixX is the Actual Linear Transformer X: A=>B. AX=B has 3 vector spaces row space, column space and null space.
Let T : V =>W be linear transformation
Range(T) is subspace of W [column space of rref matrix]
Kernel(T) is subspace of V [solution space of matrix in rref]
Nullity (T) = dim(Kernel(T))
Rank(T) = dim(Range(T))
dim(Kernel(T) + dim(Range(T)) = dim V -> Rank Nullity Theorem.
Now let us try to answer the sub questions,
1. When do we call a Transformation Unique.
A Transformation is unique if the transformation is done with the basis of Vector space V maps to nullity of Vector Space U. This is my assumption based on answer in quora
2. What is a Kernel space?
In Transformation T: V => U
Kernal space is set of vectors of V that maps to null space in U. 3. Does T : V --> W, where V and W are vectorspaces over F has any special meaning with F (i.e field)
There is no special meaning in F or Field. Vector space is a special field, instead of cross multiplication we have scalar multiplication to make the transformation linear.
4. What is the significance of Dimension of kernel space of T being 666
We can have any other number other than 666. Dimension of kernel space will be dimension is the Nullity of T and is also the subspace of V. In order for the transformation to be unique happen it should form the basis. Basis of any matrix can be identified with RREF of matrix or the transformation should result in one to one onto. To prove this we should take a smaller similar matrix similar to 666 dimension of kernel space with diagonalization and power reduction.
The actual solution for entire problem is said to be NOT POSSIBLE to have UNIQUE TRANSFORMATION, because the ---. I still did not understand.
UPDATE 1:
Post clarification with lecturer, it seems the question seems to be questioning the understanding of the completeness of the problem, with all the given constraints. The given constraint Dimension of Kernel space of T being 666, is alone not enough to determine whether it could map to UNIQUE elements in CO-DOMAIN vector space. For me IMAGE OR RANGE looks to be not enough to determine UNIQUE TRANFORMATION. The involvement of BASIS seems to be an approach, a good approach to reduce the no. of mappings from DOMAIN to CO-DOMAIN while trying to understand whether the transformation is UNIQUE especially when we are dealing with 100s of dimensions.
It was an application of diagonalization property of similar matrix.
D (diagonal matrix) = X−1AX Here X is matrix constructed from eigen vectors placed column vise.
Eigen vectors and values can be obtained with A - lambda.I = 0 equation factorization.
The above is a series convergence problem. Again an application of Diagonalization which is applicable only for similar matrix (transformation only rotates or translates no scaling or change in angle) and for eigen vector matrix (which is a similar matrix for the given matrix)
Here Lambda is given in eigen notation. since lamda1. labmda2. lamda3...... lambdan = 0 as it is the determinant of matrix as A^k tends to zero when k tends to infinite. modulus of lambda should be less than 1 or greater than -1 for alternating series. hence modulus is less than 1.
There was an question from exam paper related to rotation of values which also required application of Diagonalization of Matrix and euler formula application.
Markov Process, Information Theory and Entropy
I often remembered Markov Process during this session due to the application of diagonalization. But Markov process is bit more than linear system. The Markov chain happens to become linearly independent only when it attains the state of equilibrium and the relation between part of the system can be determined by probability of occurrence identified during equilibrium. I also learnt that I have forgotten that Gaussian distribution has Binomial distribution as another name and it is related to Binomial theorem as it take binary random variable. I came to know that One of Bernoulli did came up Expectation as an equilibrium state to find the ratio of given 2 number of items, with Weak Law of Large Numbers. I was also prompted to look into Central Limit Theorem.
Formation of Information theory from Markov Process.
Reduction is entropy takes place when the data sequence is predictable. It can be related to principle component analysis as we could reduce dimensions of data based on principle components, based on reduction found in entropy we can reduce the data sequence / amount of data that is the place where we apply encoding techniques to increase entropy again without loosing information. This is the conclusion, i could arrive with this blog last paragraph.
Vectors Spaces can be studied without Matrices and Matrices can be studied without Vector Space.
In reality when we expand the study of both, we will find that Matrices can take 3 vector spaces.
The 3 vector spaces are row space, column space and null space. These spaces also have theirbasis.
Vector Spaces of Matrices
If A is an m×n matrix
The subspace of R^n spanned by the row vectors of A is called the row space of A.
The subspace of R^m spanned by the column vectors is called the column space of A.
The solution space of the homogeneous system of equation Ax = 0, which is a subspace of R^n, is called the nullspace of A.
Basis of Matrices Vector spaces
If a matrix R is in row echelon form,
The row vectors with the leading 1’s (i.e., the nonzero row vectors) form a basis for the row space of R.
The column vectors with the leading 1’s of the row vectors form a basis for the column space of R.
I hope if there is a unique solution for matrix AX=B, then we this unique solution form the basis for null space in R. Still doubtful, but not required to be investigated further. [Found it true, Finding a basis of the null space of a matrix , was present in tool and it maps to solution space as basis] Rank of a matrix in terms of Vector Spaces
If Row and column space have equal dimensions dim(RS(A)) = dim(CS(A)) then rank(A) = dim(RS(A)) = dim(CS(A))
rank(A^T) = dim(RS(A^T)) = dim(CS(A)) = rank(A) Therefore rank(A^T ) = rank(A) Nullity of Matrix
If A is an m×n matrix of rank r, then the dimension of the solution space of Ax = 0 is n – r.
nullity(A) = dim(NS(A))
nullity(A) =n - rank(A)= n-r
n=rank(A)+nullity(A) --> Rank Nullity Theorem. Rank for solution finding
Rank we can obtain from row reduction by getting rref.
If A is an m×n matrix and rank(A) = r, then
Fundamental Space => Dimension
RS(A)=CS(AT) => r
CS(A)=RS(A^T) => r
NS(A) => n-r
NS(AT) => m-r
We can only use guassian elimination method to find rank and the get the system of equation without 0 values and replace dependent rows with substituted values, we can find the nullity. Then we can check whether rank + nullity provides dimension n of matrix (or total no. of rows).
Please try to understand Probability Distribution a little bit, especially the particular section of "Common probability distributions and their applications".
Understanding distribution of data during mining is very important as we require to find patterns.
Normal distribution is very much useful for error detection and outlier detection.
If we take Normal Curve or Bell shaped Curve or Gaussian Curve of Normal distribution. The center portion of the curve has the highest probability of an event happening. In term of data analysis, we can find around 60% falling under center part of curve.
For a symmetric curve, the mean, median and mode will be same and will fall in the center. For a skewed distribution, it will be different. We can plot an historgram chart
Normal distribution curve showing higher probability of events happening in the center of the curve.
Covering and removing errors from the distribution results in 1 sigma, 2 sigma, 3 sigma. People try to perform 6 sigma projects based on impurity reduction or error reduction in project.
The below image show what happens to mean, median and mode when normal curve is skewed.
Quantile Quantile Plot
A box-and-whisker plot or boxplot is a diagram based on the five-number summary (completely based on median, range calculation) of a data set. The skewness also can be identified with Quantile Quantile plots.
Positive skew indirectly means that some non-conformance occurrence of events helps to minimizing the entire distribution overall value / performance (despite mean remains same, median and mode shifted towards maximum)
Negative skew indirectly means that non-conformance occurrence of events helps to maximizing the entire distribution overall value / performance (despite mean remains same, median and mode shifted towards maximum) .
Below image show how Histogram is related to Normal Distribution Curve and Box Plot
Below image show how to identify the outliers from box plot. Even i above histogram there are dots representing outliers.
Kurtosis
Kurtosis is another measure of deviation from Normal Distribution just like skewness. While skewness tell us whether there is any +ve or -ve translation of the event population. Kurtosis actually tell us the way how dispersion takes place.
While Skewness holds the central axis of the distribution and and bring an external change by changing the internal axis. Kurtosis takes the external curve or external population distribution and rearranges them to smoother it or flatten it or sharpen it.
Skewness is an internal change in the behavior of population. Kurtosis is the external change in the behavior of population.
Skewness denotes a sidewards movement, while kurtosis denotes the decrease or increase of height of the bell curve with respect to population.
Spectral Radius and Spectrum of a matrix are formed by the Eigen vectors and values. I started reviewing this concept that I documented as a take away in my earlier post. While reviewing what is Spectral Radius and What is it significance, I came across a Quora Response, which gave me hint that it is related to Power Series.
So what is it (Spectrum & Spectral Radius) Significance?
I could see that any series could help us to approximation of values. And please note that there are 2 kinds of series,
1. Convergence Series - A Series which converge to a finite number (real or complex does not matter)
2. Divergent Series - A series which becomes infinite.
Spectral radius has an impact on Convergence of Matrix Power Sequence M^n and Matrix Series.
if the power series ∑j=0∞cjxjconverges for some radius of convergence |x|<r
There was a related Question in Quora related to Spectral Decomposition. Yes Spectral Decomposition is a familiar term it also is related to Frequency Decomposition (As Spectrum is essentially a decomposition of Electromagnetic radiation.
Spectral Decomposition is related to Data Mining in term of Analysis of Cube or Multidimensional data as like solving rubik cube collecting all similar colors on particular faces.
While doing Matrix decomposition, we prefer to perform spectral decomposition, this is possible with eigen vectors and values.
What is a Series? What are the other series available and why spectum is compared to power series?
If we are familiar with Arithmetic and Geometric Progression, we definitely know what is a sequence. A summation of Sequence is a Series. Both sequence and series will converge or diverge.
Greek mathematician Archimedes seems to have produced first known summation of an infinite series with a method that is still used in the area of calculus today. He used the method of exhaustion to calculate the area under the arc of a parabola with the summation of an infinite series, and gave a remarkably accurate approximation of π. There are also many approximation of π. Please find below picture, I love the way how approximation are done by converging the series to π value.
The geometric series is a simplified form of a larger set of series called the power series. A power series is any series of the following form:
Notice how the power series differs from the geometric series: In a geometric series, every term has the same coefficient. In a power series, the coefficients may be different — usually according to a rule that’s specified in the sigma notation. One can think of a power series as a polynomial with an infinite number of terms. For this reason, many useful features of polynomials carry over to power series. Matrices are actually polynomials of linear order, so i hope there is no surprise when power series comes into the Picture.
Little bit More about Series
The well know series based on the sequences are as below,
The Power Series is very interesting for Polynomial Analysis as it is related to much of the other interesting series and very much relevant to mining and data science especially in terms of dimensional reduction with spectral decomposition.
I created a Youtube playlist with few videos related to series - check this out






![{\displaystyle \left[\mathbf {a} \cdot \mathbf {b} \right]=\mathbf {a} ^{\operatorname {T} }\mathbf {b} ,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/df7fe45515e81c3a4160801b7f9658f3a84af1b8)












































