The main reason for the review is to summarize my takeaways from the blog.
The writer of the blog is a data scientist working in Airbnb and has also worked in Twitter. The blog is a writing of his understanding about his Adjacent field Data Engineering. I read many links provided in his blogs including his blogs on Data Science where he documents his work experience and also read an article about "Mastering Adjacent Disciplines".
His Main Objective for the blog was to document his learning of the Adjacent Disciplines.
Let me first summarize the points to take away in "Mastering Adjacent Disciplines"
1. First figure out what are your Adjacent discipline. Like the blogger, I am an aspirant data scientist, wanted to understand data engineering as an adjacent discipline. let us understand Adjacent discipline through examples and figure out what is it.
Product engineer, adjacent disciplines might include user interface design, user research, server development, or automated testing.
For Infrastructure engineer, they might include database internals, basic web development, or machine learning.
User growth engineers could benefit by increasing their skills in data science, marketing, behavioral psychology, and writing.
For technical or project leads, adjacent disciplines might include both product management and people management.
And if you’re a product manager or designer, you might learn to code.2. Understand the benefits to expend efforts
You will become self-sufficient and effective in your day-to-day job.
Gives you the flexibility to potentially tackle those areas on your own.
In comparison to learning a completely unrelated but perhaps still valuable discipline, you’re almost guaranteed to use these new skills you acquire in your day-to-day work.
It benefits you and your team by increasing empathy of your team mates with other teams.Let me also finish of with my takeaways from blog of the writer on Data Science.
1. We are not expected to be Unicorns, Unicorns do exists. I like to become one Unicorn.
Data science is not Teenage sex. i definitely know this. But we can't help people speaking about it like Teenage sex. They are just Marketing, Sales motivators but over-emphasizes real Data Scientist role and the need of Data Science.
All DS need not be unicorns with expertise from Math/Stat, CS/ML/Algorithms, to data. We don't have such demands in the industry but Unicorns do exists.2. There are 2 types of Data Scientist. My skills and opportunities are almost of that of Type B, I had to move towards Type A to add more meaning to the domain of operation.
Type A Data Scientist: The A is for Analysis. This type is primarily concerned with making sense of data or working with it in a fairly static way. The Type A Data Scientist is very similar to a statistician (and may be one) but knows all the practical details of working with data that aren’t taught in the statistics curriculum: data cleaning, methods for dealing with very large data sets, visualization, deep knowledge of a particular domain, writing well about data, and so on.
Type B Data Scientist: The B is for Building. Type B Data Scientists share some statistical background with Type A, but they are also very strong coders and may be trained software engineers. The Type B Data Scientist is mainly interested in using data “in production.” They build models which interact with users, often serving recommendations (products, people you may know, ads, movies, search results).3. Where to land for a Job and what will be the nature of work? I have taken the startup as "investigation start" on data and not as a startup company. All I had dream seem to fall only in scaled companies. I am currently under some early start up stage :(
At early stage start-ups: the primary analytic focus is to implement logging, to build ETL processes, to model data and design schemas so data can be tracked and stored. The goal here is focused on building the analytics foundation rather than analysis itself.
At mid-stage growing start-ups: Since the company is growing, the data is probably growing too. The data platform needs to adapt, but with the foundation laid out already, there will be a natural shift to insight generation. Unless the company leverages Data Science for its strategic differentiation to start with, many analytics work are around defining KPI, attributing growth, and finding the next opportunities to grow.
Companies who achieved scale: When the company scales up, data also scales up. It needs to leverage data to create or maintain competitive edge. e.g. Search results need to be better, recommendations need to be more relevant, logistics or operations need to be more efficient — this is the time where specialist like ML engineers, Optimization experts, Experimentation designers can play a huge role in stepping up the game.4. Understand the Job Nature as a whole. I am Nowhere near here. It is well taken, it is completely a different world. I shall move from Nowhere to Now here.
Skill that are required - Programming, Analytical and Experimentation.Hope that convinced you to read my blog further despite you being a data scientist aspirant just like me. Let me also put forth my take away with respect to "Data Engineering" blog.
Understanding of Infrastructure & Data pipelines - the Product, Instrument, Experiment, A/B test and Deploy
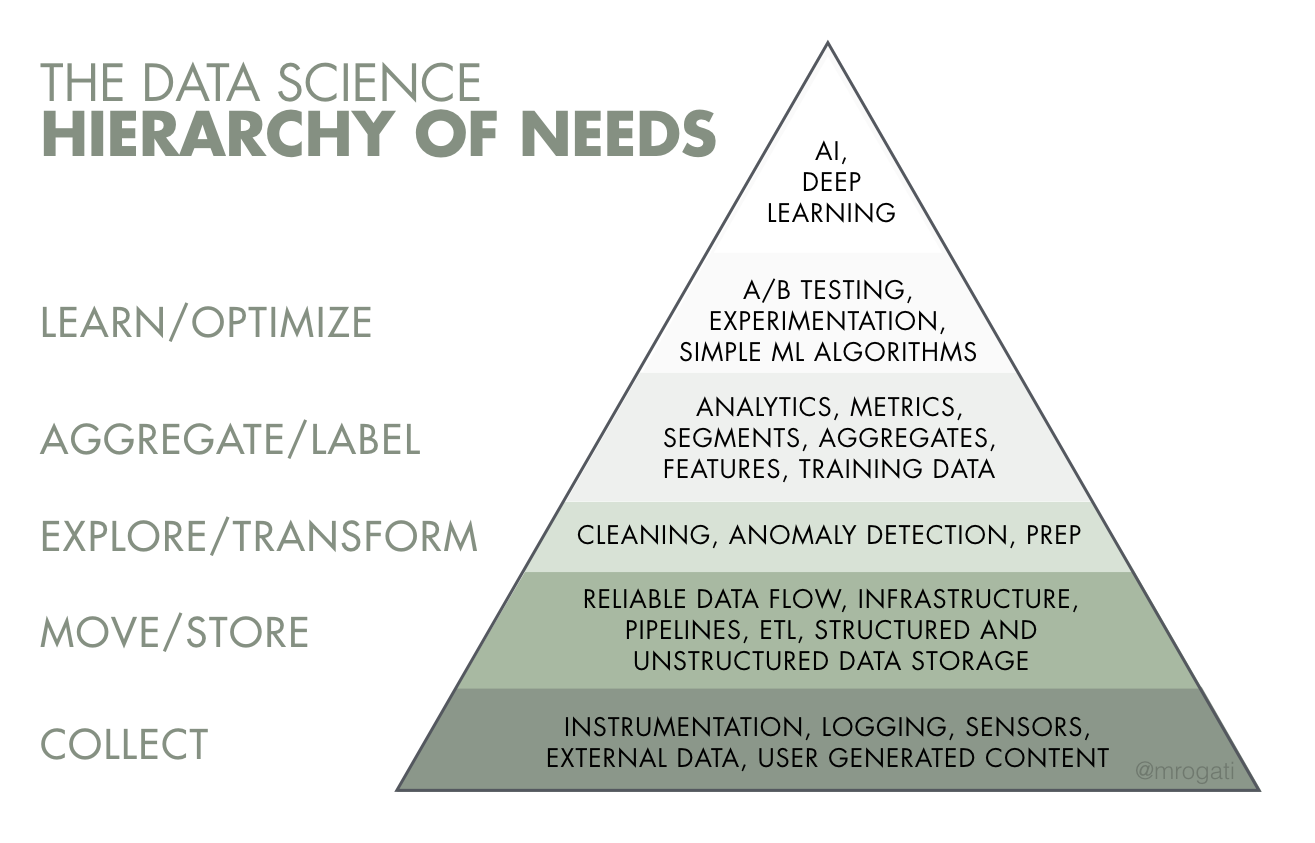
1. Monica Rogati’s call out
Think of Artificial Intelligence as the top of a pyramid of needs. Yes, self-actualization (AI) is great, but you first need food, water, and shelter (data literacy, collection, and infrastructure).
2. Better understanding of "Data Engineering" field
The data engineering field could be thought of as a superset of business intelligence and data warehousing that brings more elements from software engineering. This discipline also integrates specialization around the operation of so called “big data” distributed systems, along with concepts around the extended Hadoop ecosystem, stream processing, and in computation at scale.
A link reference from the writer blog led to The Rise of the Data Engineer. Where I could make better sense of Data Engineering field.
1. The need for flexible ETL tools lead to developement of new ETL tools like Airflow, Oozie, Azkabhan or Luigi.
2. Old ETL tools which had drag and drop facilities like Informatica, IBM Datastage, Cognos, AbInitio or Microsoft SSIS have become obsolete.
3. New ETL tools provides flexibility and abstractions to maintain experiments, schedule experiments, allow A/B testing. They are more Open Systems.
4. Data modeling has changed - Much denormalization possiblities, better blob support, dynamic creation of schemas, snapshoting and conformane of dimensions of schemas have become less imperative.
5. Datawarehouse is the gravity around which data engineering still moves around. Yet Datawarehouse is also publicly shared with Data Scientist & Analyst. It has become to much Centric to the IT organization as a whole, rather than Data Engineer being its owner.
6. Heavy performance tuning & optimization are being achieved as more money is invested to pour in more data and experiment with same resources.
7. Data Integration from SAAS based OLTP applications have become difficult. Non Standard and Changing API of OLTP systems are disrupting OLAP system.
3. ETL Paradigms: JVM based ETLs and SQL based ETLs are two track of choice.
4. Understanding of Job Nature of "Data Engineer"
Build Data Warehouses with ETLs and managing data pipelines (DAG - Directed Acyclic graphs).
Data modeling (Data Normalization and Star Schema), Data Partitioning and back filling historical records. Fact and Dimension Tables.5. Understanding the need of moving from pipelines to frameworks.
Standalone pipelines to Dynamic pipelines have become need of the hour. It is now possible by constructing DAG via simple configuration files such yaml and has to deploy well known patterns as frameworks.
Incremental Computation Framework
To avoid full table scans for aggregation functions, this framework pre-calculating them daily, monthly, quarterly and avoids them when data scientist does such operations.
Back fill Framework
Back filling of historical or update records is a tedious job. But it will have to take frequently, such jobs are run with this framework.
Global Metrics Framework
De-normalization Machines to make Dimensional cut based metrics to build de-normalized schema automatically as required for both data scientist and market facing business people
Experimentation Reporting Framework
Every data company builds experimental models in a modular fashion which remains very lengthy than production models. These most complex ETL jobs have to executed and statistical calculation are captured per module instead of complete workflow to make decisions.




No comments:
Post a Comment